Machine Learning #3 : 범주형 변수 변황 (one hot encoding)¶
자료 출처 : Datacampus "빅데이터 분석기사 자격증 과정 실기" 책 예제 : https://www.datacampus.co.kr/board/read.jsp?id=98394&code=notice
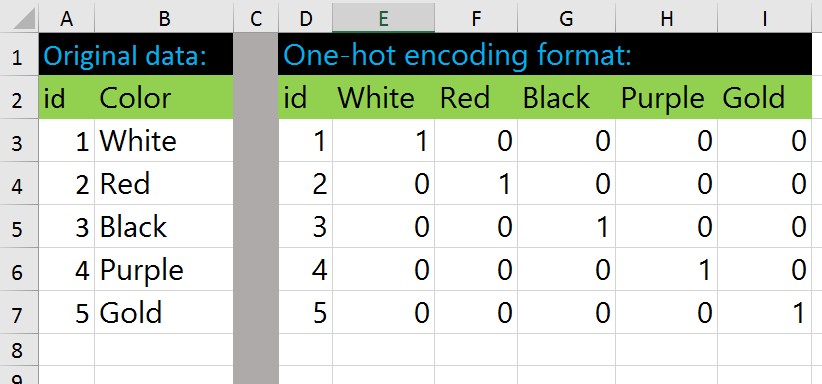
one hot encoding 예시¶
data/library import¶
In [8]:
import warnings
warnings.filterwarnings('ignore')
In [12]:
import pandas as pd
data=pd.read_csv('vote.csv')
print(data.info())
data.head()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 211 entries, 0 to 210 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 gender 211 non-null int64 1 region 211 non-null int64 2 edu 211 non-null int64 3 income 211 non-null int64 4 age 211 non-null int64 5 score_gov 211 non-null int64 6 score_progress 211 non-null int64 7 score_intention 211 non-null float64 8 vote 211 non-null int64 9 parties 211 non-null int64 dtypes: float64(1), int64(9) memory usage: 16.6 KB None
Out[12]:
| gender | region | edu | income | age | score_gov | score_progress | score_intention | vote | parties | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 4 | 3 | 3 | 3 | 2 | 2 | 4.0 | 1 | 2 |
| 1 | 1 | 5 | 2 | 3 | 3 | 2 | 4 | 3.0 | 0 | 3 |
| 2 | 1 | 3 | 1 | 2 | 4 | 1 | 3 | 2.8 | 1 | 4 |
| 3 | 2 | 1 | 2 | 1 | 3 | 5 | 4 | 2.6 | 1 | 1 |
| 4 | 1 | 1 | 1 | 2 | 4 | 4 | 3 | 2.4 | 1 | 1 |
data set 나누기¶
In [13]:
x1=data[['gender','region']]
xy=data[data.columns.tolist()[2:]]
In [17]:
xy
Out[17]:
| edu | income | age | score_gov | score_progress | score_intention | vote | parties | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 3 | 3 | 2 | 2 | 4.0 | 1 | 2 |
| 1 | 2 | 3 | 3 | 2 | 4 | 3.0 | 0 | 3 |
| 2 | 1 | 2 | 4 | 1 | 3 | 2.8 | 1 | 4 |
| 3 | 2 | 1 | 3 | 5 | 4 | 2.6 | 1 | 1 |
| 4 | 1 | 2 | 4 | 4 | 3 | 2.4 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 206 | 1 | 4 | 4 | 3 | 3 | 1.8 | 1 | 2 |
| 207 | 2 | 1 | 2 | 3 | 4 | 2.6 | 1 | 4 |
| 208 | 2 | 1 | 2 | 3 | 3 | 2.6 | 1 | 2 |
| 209 | 2 | 3 | 4 | 3 | 2 | 4.0 | 1 | 4 |
| 210 | 2 | 2 | 2 | 3 | 3 | 3.8 | 1 | 2 |
211 rows × 8 columns
범주형 변수 실제 값을 변환하기¶
In [14]:
x1['gender']=x1['gender'].replace({1:"male",2:"female"})
x1.head()
Out[14]:
| gender | region | |
|---|---|---|
| 0 | male | 4 |
| 1 | male | 5 |
| 2 | male | 3 |
| 3 | female | 1 |
| 4 | male | 1 |
In [15]:
x1['region']=x1['region'].replace([1,2,3,4,5],['Sudo',"Chungcheung","Honam","Youngnam","Others"])
x1.head()
Out[15]:
| gender | region | |
|---|---|---|
| 0 | male | Youngnam |
| 1 | male | Others |
| 2 | male | Honam |
| 3 | female | Sudo |
| 4 | male | Sudo |
범주형 변수 변환 : pd.get_dummies()이용¶
In [16]:
x1_dum=pd.get_dummies(x1)
x1_dum.head()
Out[16]:
| gender_female | gender_male | region_Chungcheung | region_Honam | region_Others | region_Sudo | region_Youngnam | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
In [18]:
Fvote=pd.concat([x1_dum,xy],axis=1)
Fvote.head()
Out[18]:
| gender_female | gender_male | region_Chungcheung | region_Honam | region_Others | region_Sudo | region_Youngnam | edu | income | age | score_gov | score_progress | score_intention | vote | parties | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 3 | 3 | 3 | 2 | 2 | 4.0 | 1 | 2 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 2 | 3 | 3 | 2 | 4 | 3.0 | 0 | 3 |
| 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 2 | 4 | 1 | 3 | 2.8 | 1 | 4 |
| 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 1 | 3 | 5 | 4 | 2.6 | 1 | 1 |
| 4 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 2 | 4 | 4 | 3 | 2.4 | 1 | 1 |
자료 저장하기¶
In [19]:
Fvote.to_excel("onehotencoding_Fvote.xlsx")
In [20]:
Fvote.to_csv("onehotencoding_Fvote.csv")
In [ ]:
'빅데이터분석기사 자료 > 2) 빅.분. 기 - ML' 카테고리의 다른 글
| [빅.분.기] 작업형2유형 - 랜덤포레스트 (0) | 2022.02.23 |
|---|---|
| [빅.분.기] 작업형2유형 - 문제 연습 (0) | 2022.01.08 |
| [빅.분.기] 작업형2유형 - Train/Test 셋 분리 (0) | 2022.01.08 |
| [빅.분.기] 작업형2유형 - Logistic회귀 (0) | 2022.01.08 |
댓글